Have been working with Databricks since 2018 and there are so many different gems that make life a lot more easier. One of the most used features has been the Databricks SQL Connector. This can be a very powerful tool when building solutions that need to use Data from Databricks.
Official documentation for the api can be found from here Statement Execution API: Run SQL on warehouses.
Prerequisites
Before getting started you need to have few things:
- Databricks workspace
- Databricks SQL warehouses (can be the default)
- Access token(PAT)
- databricks-sql-connector (python package installed)
Setup
pip install databricks-sql-connector
In this example I use Streamlit, so install streamlit
pip install streamlit
Auth
There are several options to authenticate with Databricks, the full list can be found from here
For none production options you can use PAT token. this can be found under settings -> Developer -> Access tokens -> Manage -> Generate new token. Details instructions
Lets get the data!
Creating the connection lets use the databricks-sql-connector. It is identically the same as running any database connection.
from databricks import sql
connection = sql.connect(
server_hostname = 'xxxxx.azuredatabricks.net',
http_path = '/sql/1.0/warehouses/xxxx',
access_token = 'PAT')
cursor = connection.cursor()
Now that you have the connection, lets query data.
from databricks import sql
connection = sql.connect(
server_hostname = 'xxxxx.azuredatabricks.net',
http_path = '/sql/1.0/warehouses/xxxx',
access_token = 'PAT')
cursor = connection.cursor()
cursor.execute("select * from samples.tpch.customer") #this data can be found from any databricks account
print(cursor.fetchall())
cursor.close()
connection.close()
Now you are done!
NB! If the query takes too much time, the sql warehouse is not turned on or dataset that you are trying to query is too large. Optimizing your query so that you withdraw only values that you need makes it faster.
Streamlit
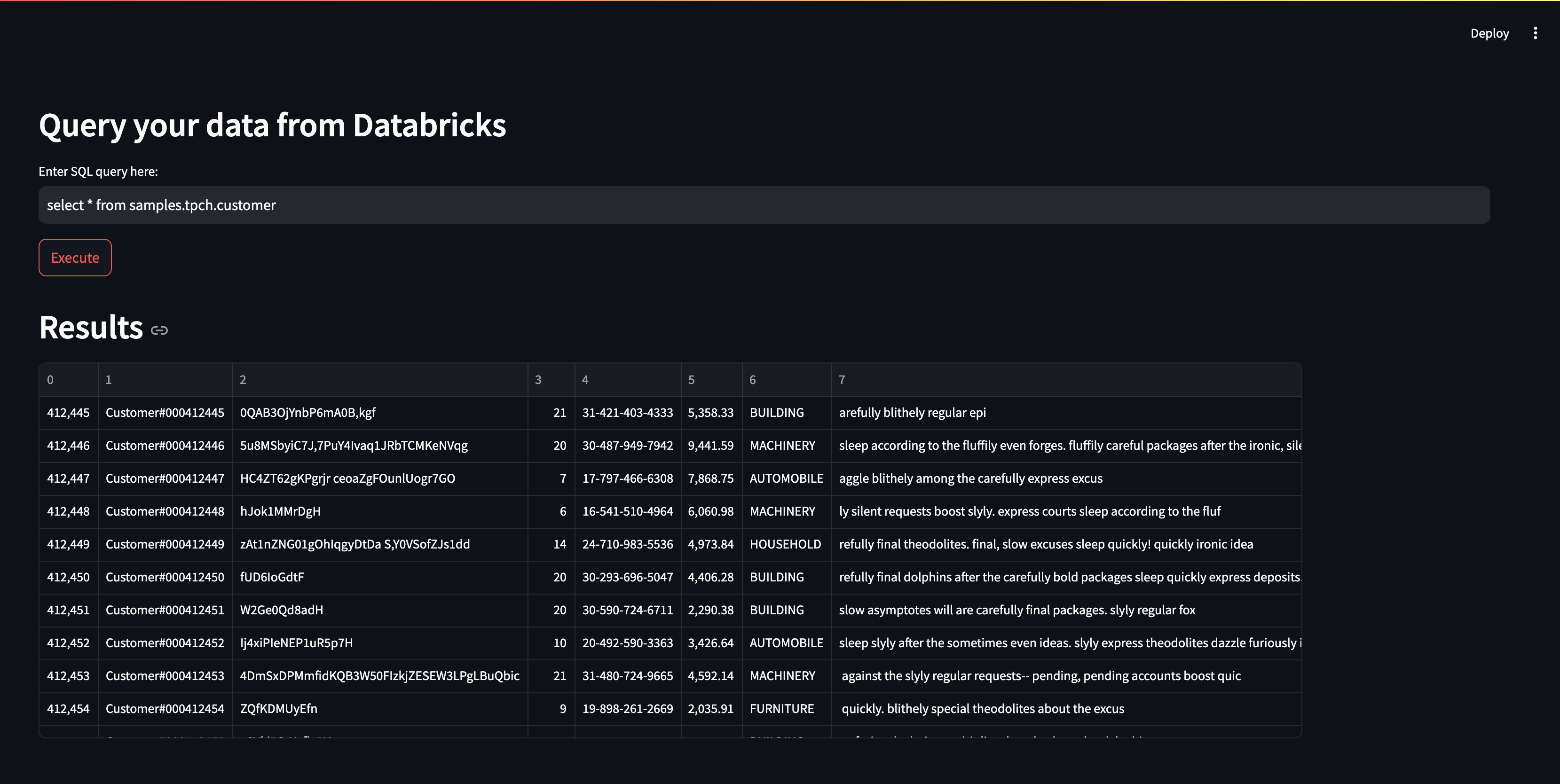
Combining different datasets or just visualizing the data, Streamlit can be an option, if you don’t want to load the data and just query. Here is an example how to use streamlit for getting the data.
I have added the secrets into the secrets.toml file. Here is an example:
import streamlit as st
from databricks import sql
import os
st.set_page_config(layout="wide")
connection = sql.connect(
server_hostname = st.secrets["workspace"],
http_path = st.secrets["http_path"],
access_token = st.secrets["pat"])
cursor = connection.cursor()
st.header("Query you data from Databricks")
query = st.text_input("Enter SQL query here:")
if st.button("Execute"):
cursor.execute(query)
st.header("Results")
st.dataframe(cursor.fetchall(), width=False)
cursor.close()
connection.close()
Conclusion
Databricks Execution API is for building solutions. With the help of the databricks-sql-connector and a PAT token, you can easily connect to your Databricks workspace and query data. Additionally, Streamlit can be used to visualize the data and make querying even easier. By optimizing your queries and only withdrawing the values you need, you can make the process faster. Overall, the Databricks Execution API is a great tool for anyone working with Databricks.
Happy coding
The code can be found from github Github link