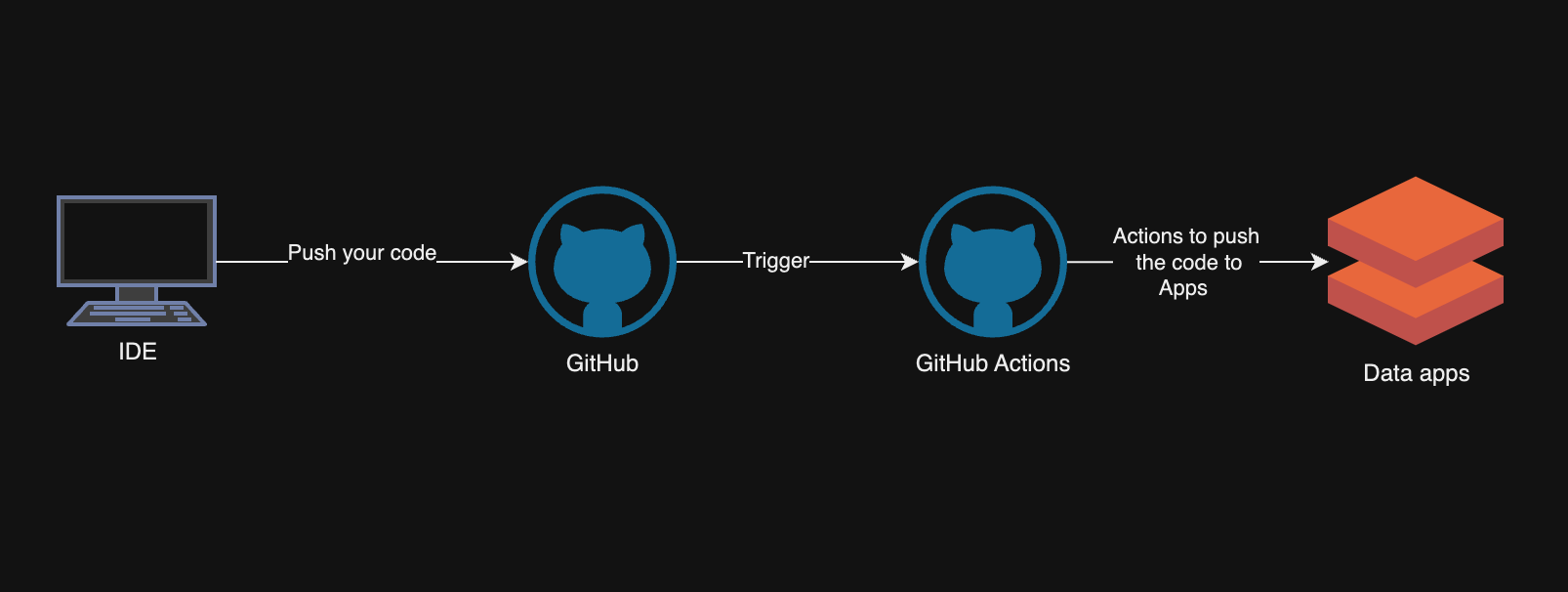
Data apps and Deployment with GitHub Actions
Databricks data apps are now in public preview available. This example can be used for all the app deployment. The processes itself doesn’t take into account what apps are in question. Databricks supports the following frameworks: Dash, Flask, Gardio, Shiny and Streamlit.
This blog is about how to deploy apps, not so much about how to develop the apps. This example is Azure related and can be different for AWS and GCP.
Pre tasks
Before you begin, ensure you have the following:
- A GitHub repository
- Databricks workspace
- Service principal for the ci/cd
- Sql enpoint
Create a service principal for the deployment. Depending on your Databricks setup, you can either create an Entra or Databricks managed(obo) service principal.
Detailed instructions can be found from here
Github CI/CD
If you want to jump to the code, the code can be found from here
1. Install the databricks cli
This step uses the actions/checkout action to clone the repository into the workflow runner. This is necessary for the subsequent steps to access the code and configuration files in the repository.
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
2. Get Databricks Access Token using Service Principal
This step installs the Databricks CLI, which is a command-line tool for interacting with the Databricks platform. The CLI is essential for performing various operations such as syncing files and managing apps. In this case you can also limit the lifetime of the token and what apis you want to access, we will access all.
- name: Get Databricks Access Token using Service Principal
run: |
export CLIENT_ID=${{ secrets.DATABRICKS_CLIENT_ID_CICD }}
export CLIENT_SECRET=${{ secrets.DATABRICKS_CLIENT_SECRET_CICD }}
export TOKEN_ENDPOINT_URL="${{ secrets.DATABRICKS_HOST }}/oidc/v1/token"
DATABRICKS_TOKEN=$(curl --request POST \
--url "$TOKEN_ENDPOINT_URL" \
--user "$CLIENT_ID:$CLIENT_SECRET" \
--data 'grant_type=client_credentials&scope=all-apis' | jq -r .access_token)
echo "DATABRICKS_TOKEN=$DATABRICKS_TOKEN" >> $GITHUB_ENV
3. Create Databricks Directory for Apps
This not necessary if you want to use the direct folders from users that are connected with databricks.
This step syncs the local ./apps/ directory with the /apps directory in Databricks. This ensures that the latest version of the applications is uploaded to Databricks.
There can be as several apps, the limit is 10 apps per/workspace, and they can be any of the supported apps mentioned in the beginning. The deployment pipeline doesn’t check the app framework.
- name: Create Databricks Directory for apps
run: |
RESPONSE=$(curl --request POST \
--url "${{ secrets.DATABRICKS_HOST }}/api/2.0/workspace/mkdirs" \
--header "Authorization: Bearer $DATABRICKS_TOKEN" \
--header "Content-Type: application/json" \
--data '{"path": "/apps"}')
echo "response=$RESPONSE" >> $GITHUB_ENV
echo "$RESPONSE"
4. Create Databricks App if Not Exists
databricks sync ./apps/ /apps –full: This command uses the Databricks CLI to synchronize the local ./apps/ directory with the /apps directory on Databricks. The –full flag indicates that a full synchronization should be performed, ensuring that the contents of the local directory are fully mirrored to the remote directory.
- name: Databricks sync
env:
DATABRICKS_HOST: ${{ secrets.DATABRICKS_HOST }}
DATABRICKS_TOKEN: ${{ env.DATABRICKS_TOKEN }}
run: |
echo "Checking out the releases branch"
databricks -v
databricks sync ./apps/ /apps --full
5. Create Databricks App if Not Exists
This step in the GitHub Actions workflow ensures that Databricks apps are created if they do not already exist. It performs the following actions:
Environment Variables :
DATABRICKS_HOST: The Databricks host URL, retrieved from GitHub secrets.DATABRICKS_TOKEN: The Databricks access token, retrieved from the environment variables.
Loop Through Directories :
- The script iterates over each directory inside the
appsdirectory. - It skips hidden directories (those starting with a dot).
Create App :
- For each app directory, it attempts to create a new Databricks app using the Databricks API.
- If the app already exists, it skips the creation process.
- It will also allow the app to use the Sql endpoint and app service principal to permissions
Check App Status :
- If the app is newly created, the script waits until the app’s status becomes
ACTIVE. - It checks the app status every 30 seconds.
Deploy App :
- Once the app is
ACTIVE, it deploys the app using thedatabricks apps deploycommand.
- name: Create Databricks app if not exists
env:
DATABRICKS_HOST: ${{ secrets.DATABRICKS_HOST }}
DATABRICKS_TOKEN: ${{ env.DATABRICKS_TOKEN }}
SQL_WAREHOUSE: ${{ secrets.SQL_WAREHOUSE }}
run: |
for app_dir in $(find apps -mindepth 1 -maxdepth 1 -type d); do
app_name=$(basename "$app_dir")
if [[ $app_name == .* ]]; then
echo "Skipping hidden directory: $app_name"
continue
fi
echo "Processing app: $app_name"
RESPONSE=$(curl --request POST \
--url "${{ secrets.DATABRICKS_HOST }}/api/2.0/apps" \
--header "Authorization: Bearer $DATABRICKS_TOKEN" \
--header "Content-Type: application/json" \
--data "{\"name\": \"$app_name\", \"default_source_code_path\": \"/apps/$app_name\", \"resources\": [{\"sql_warehouse\": {\"id\": \"$SQL_WAREHOUSE\", \"permission\": \"CAN_MANAGE\"}}]}")
echo "response=$RESPONSE" >> $GITHUB_ENV
echo "Create app $RESPONSE"
if echo "$RESPONSE" | grep -q "ALREADY_EXISTS"; then
echo "App $app_name already exists. Skipping creation."
else
# Wait until the app is in the ACTIVE state
while true; do
APP_STATUS=$(curl --request GET \
--url "${{ secrets.DATABRICKS_HOST }}/api/2.0/apps/$app_name" \
--header "Authorization: Bearer $DATABRICKS_TOKEN" | jq -r .compute_status.state)
if [[ "$APP_STATUS" == "ACTIVE" ]]; then
echo "App $app_name is ACTIVE"
break
fi
echo "Waiting for app $app_name to become ACTIVE. Current state: $APP_STATUS"
sleep 30
done
fi
#This will make sure that the app will update
databricks apps deploy $app_name --source-code-path /Workspace/apps/$app_name
done
Things to do for production
** Access management
When you create an app, it needs access to sql endpoint for accessing data
The service principals that are automatically created in the deployment should be added to a relevant group. This is for accessing data.
There is also an option to give access to everyone in the organisation.
Example apps
The example apps are all the same. Streamlit apps show how to use editable dataframes.
NB! If you want the app to work you need to add the cluster id and also create a catalog app_dev, schema default and people. Also add service principal to access the underlying data. For some reason the varibles don’t work correctly.
Conclusions
The apps and the APIs are still in preview, so they can give you some grey hair. I think having a CI/CD pipeline ready for developing apps makes the development process much easier, both from the testing and quality points of view. Access management will require a lot of work if you have many workspaces and networking restrictions between different catalogs.